The Postgres Renaissance: A Modern Reawakening
Dissecting the recent revival of the iconic Database

Welcome to issue #10 of Indiscrete Musings
I write about the world of Cloud Computing and Venture Capital and will most likely fall off the path from time to time. You can expect a bi-weekly to monthly update on specific sectors with Cloud Computing or uncuffed thoughts on the somewhat opaque world that is Venture Capital. I’ll be mostly wrong and sometimes right. Views my own.
Please feel free to subscribe, forward, and share. For more random musings, follow @MrRazzi17
I have to say, I feel like I’ve been living under a rock for the past 20 years. Throughout the last couple of months, I’ve constantly been diving into the world of data infrastructure, and one of the most common things I’ve heard is: “Oh yeah, we can do that with Postgres.” Being utterly naive to the power of the popular relational database, I felt that I could no longer avoid the utility and elasticity (pun intended) of the beloved relational database. Postgres is going through a transformative renaissance: It’s beloved by its users, its community continues to grow, it has one of the most vigorous extensions of open-source communities (and remains one of the most well-maintained communities compared to the other RDBMs), the incumbents are highly cost-prohibitive (yes, you AWS RDS/Aurora) and lastly, no one wants to manage their databases anymore.
This confluence of tailwinds led me to speak with some of the brightest minds in the industry—and I couldn’t be more excited to share some of my learnings with you all. Postgres can’t solve *everything,* but its powers are hard to ignore. Most database usage is tied to the application for which it is being used; with the recent enhancements in AI/LLMs, the data layer remains absolute in its need to constantly evolve to support data-intensive applications. Postgres continues to be more than a utility and develops with the application layer despite multiple technology shifts (e.g., cloud to AI) across decades.
Relational Database Management System (RDBMS)
A brief primer—an Open Source Relational Database Management System (RDBMS) is a database management system where the software's source code is made available to the public, allowing anyone to view, modify, and distribute the code freely. These systems are typically designed to store, manage, and retrieve data in a structured manner, emphasizing the relational model of data, which organizes information into tables with rows and columns. The most common language for querying and manipulating data in RDBMS is SQL (Structured Query Language). Some advantages include:
It’s Cost Effective: Open-source RDBMS software is usually free to use, which can significantly reduce the cost of database management for organizations.
Transparent: The open-source nature of these systems allows developers to examine the source code, ensuring transparency and enabling them to identify and fix issues or customize the software to suit their needs.
Beloved Community Support: Open-source RDBMS often have vibrant communities of users and developers who contribute to documentation, support forums, and the development of add-ons and extensions.
Flexible: Users can modify the software to meet specific requirements, making it highly adaptable to various use cases.
Secure: Security vulnerabilities can be identified and fixed quickly with more considerable community involvement.
RDBMS like PostgreSQL, SQLite, and MySQL are essential for modern data storage and retrieval. Each of these systems has its unique features, strengths, and use cases, making them suitable for various applications. Here, we'll delve into the key differences between these three popular RDBMS.
PostgreSQL: PostgreSQL is often hailed for its robustness and extensibility. It's an open-source RDBMS known for supporting advanced data types, SQL compliance, and ACID (Atomicity, Consistency, Isolation, Durability) compliance. PostgreSQL's extensibility allows developers to add custom functions and data types, making it a versatile choice for complex applications. It strongly focuses on data integrity, offering features like foreign keys, triggers, and check constraints. Additionally, PostgreSQL supports NoSQL features through its hstore and JSON data types, making it an attractive option for applications requiring hybrid data models.
SQLite: SQLite, in contrast, is a serverless, file-based database engine. It is self-contained and doesn't require a separate server process, which makes it incredibly lightweight and suitable for embedded systems and mobile applications. SQLite is known for its simplicity and ease of use. It's a transactional database that follows the ACID properties, but it may not be the best choice for highly concurrent or high-transaction environments due to its file-based nature. Developers appreciate SQLite's zero-configuration and serverless design for quick deployment.
MySQL: MySQL is a popular open-source RDBMS widely adopted in web development. It's known for its speed, reliability, and ease of use. MySQL offers various storage engines, each with its strengths. InnoDB, for example, provides support for foreign keys and transactions, making it suitable for applications requiring high data integrity. MySQL is often used in web hosting environments, as it pairs well with PHP and other scripting languages. Its ecosystem includes tools and technologies for high availability, scaling, and management, making it a solid choice for web applications.
Why PostgreSQL?

The origins of Postgres date back to 1986 when it started as the Postgres project at the University of California, Berkeley, led by Professor Michael Stonebraker. The project, since, has had more than 35 years of enhancement and development, in part due to the active open-source community. More recently, Postgres has been eating other relational databases for some of the reasons below:
Extensibility and Customizability: PostgreSQL is renowned for its extensibility, which allows developers to create custom data types, functions, and operators. This feature makes it exceptionally versatile and adaptable to complex data requirements. Whether you need to implement advanced data structures or develop specific data processing logic, PostgreSQL provides the tools to do so.
Data Integrity and ACID Compliance: PostgreSQL strongly emphasizes data integrity. It supports ACID transactions, ensuring that data remains consistent and reliable despite system failures. This makes it a robust choice for applications where data accuracy is critical, such as financial systems and e-commerce platforms.
Advanced Features: Postgres offers a wide array of advanced features, including support for geographic data via PostGIS, full-text search capabilities, and native JSON and JSONB data types for semi-structured data. These features make it suitable for complex data manipulation and analysis applications.
Scalability: PostgreSQL is designed to handle both small-scale and large-scale applications. It can be effectively scaled horizontally or vertically to accommodate growing workloads, making it an excellent choice for startups and enterprises alike.
Cross-Platform Compatibility: PostgreSQL is available on multiple operating systems, making it versatile for various deployment scenarios. Whether you're running Linux, Windows, macOS, or other platforms, PostgreSQL can easily be deployed.
The Resurgence
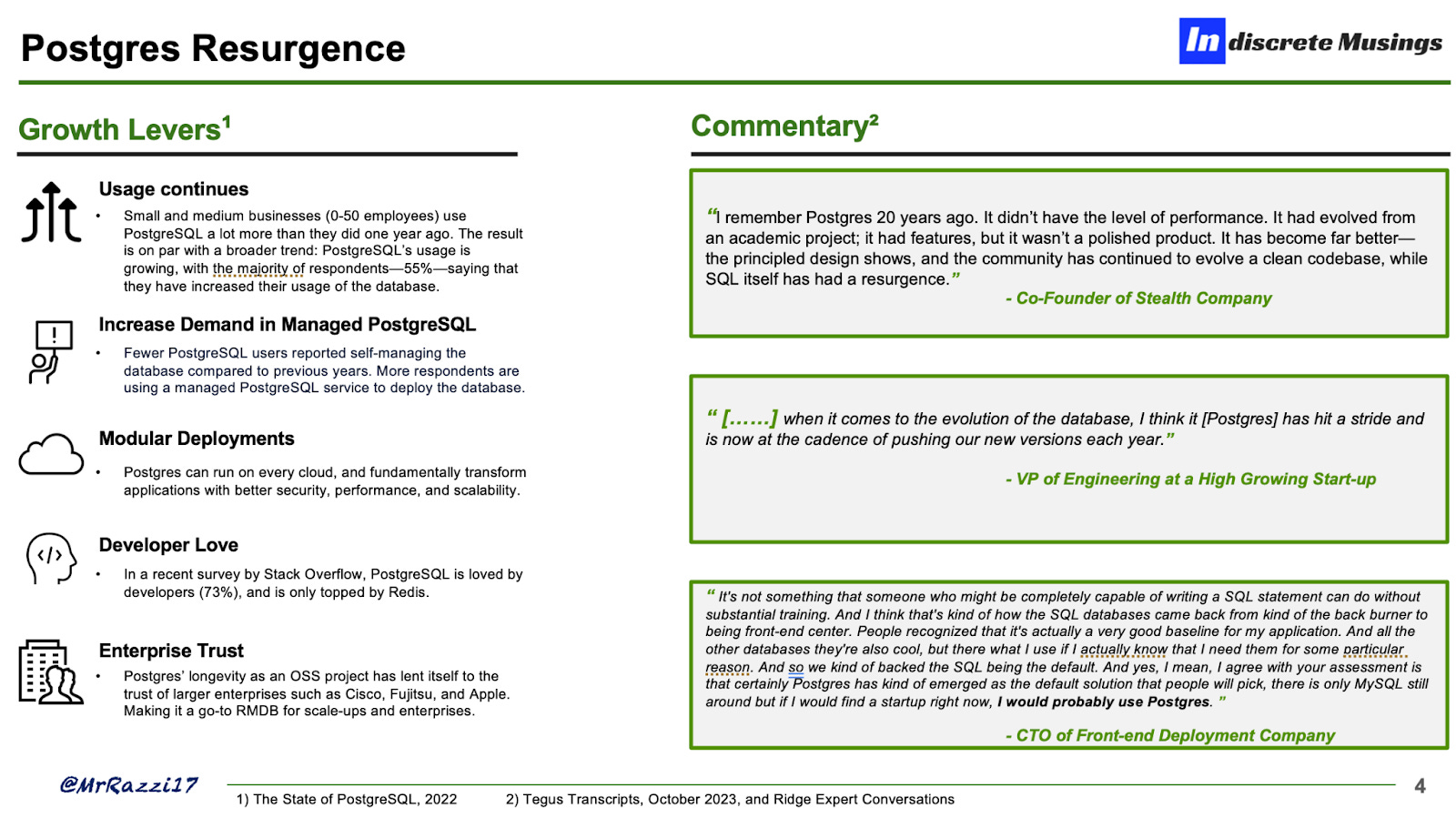
Postgres outpaces legacy and specialty databases in the most crucial of contexts—namely technical performance, flexibility, and applicability across a broad number of enterprise workloads, including a large number of Generative AI use cases in large part thanks to pgvector, which allows for vector similarly search. (I’ll revisit the Generative AI use cases later in the post.)
Postgres alone continues to be adopted and used by larger tech companies (e.g., Apple), attesting to its scalability and reliability. Apple's iCloud service relies on PostgreSQL to manage user data, showcasing the database's ability to handle massive volumes of user information securely. Its elasticity has lent itself to adapting to the world of the cloud hyper scalers, AWS, which offers Amazon RDS and Aurora for PostgreSQL, a managed PostgreSQL service. In addition to AWS, Microsoft Azure and GCP also have their offering, which is indicative of large enterprise appetites and support for large enterprise workload (e.g., need for concurrency and real-time analytics).

PostgreSQL's extension, PostGIS, has gained prominence in geospatial and location-based applications. Uber utilizes PostGIS for real-time geospatial analytics and routing. And, of course, I’d be remiss if I didn’t talk about the recent Generative AI craze and its effect on propping up Postgres—companies working on Natural Language Generation (NLG) solutions often use PostgreSQL to store and manage large corpora of text data. For example, ChatGPT utilizes PostgreSQL to organize and store training data, enabling the model to generate coherent and contextually relevant text. PostgreSQL's extensibility allows teams to create custom functions and operators for text and data transformation tasks. This is especially valuable when working with unstructured text data, as it can be transformed into structured formats for training generative models. Organizations developing AI chatbots or virtual assistants may store vast conversational datasets in Postgres, facilitating the retrieval and preprocessing of training data. Developers can use Postgres as the backend database for applications involving generative models, allowing them to retrieve and manipulate data efficiently. It is also employed to store pre-trained generative models and inference results. When models generate content on the fly, Postgres is a reliable data store for both the models and the generated content, ensuring low-latency responses to user queries.
State of Affairs

Incumbent-managed PostgreSQL providers, such as AWS, GCP, Azure, and Oracle, to name a few, offer specialized and enterprise-grade Postgres. AWS, as previously mentioned, provides Amazon RDS/Aurora for Postgres, which offers automated backup and patch management, automatic failover, and integration with other AWS services like Amazon CloudWatch for monitoring and AWS Identity and Access Management (IAM) for enhanced security. GCP offers Cloud SQL for PostgreSQL and AlloyDB, which benefits from Google's global infrastructure, ensuring low latency and high availability. It also integrates with other GCP services, such as BigQuery for analytics and Cloud Monitoring for performance tracking. Microsoft Azure boasts Azure Database for PostgreSQL, and Oracle provides Oracle Cloud Database for PostgreSQL, a managed service that combines the power of PostgreSQL with Oracle's enterprise expertise. It includes advanced security features and integration with Oracle's broader cloud ecosystem.
These incumbent-managed PostgreSQL providers deliver a combination of scalability, security, high availability, and performance, making them a preferred choice for enterprises looking to deploy PostgreSQL in the cloud or on-prem. It’s also highly lucrative for new entrants. Considering the amount of spend across F5000—it’s rumored that Aurora/RDS continues to be the fastest growing service at AWS, which is representative of large contracts such as ~$3M per annum—I couldn’t think of a more massive opportunity to supplant large incumbents within infra. Outside of the larger incumbents, you also have established providers such as DigitalOcean, CockroachDB, Heroku, and Percona, among others, with disruptors fundamentally changing the industry such as Neon, Superbase, and Vercel,
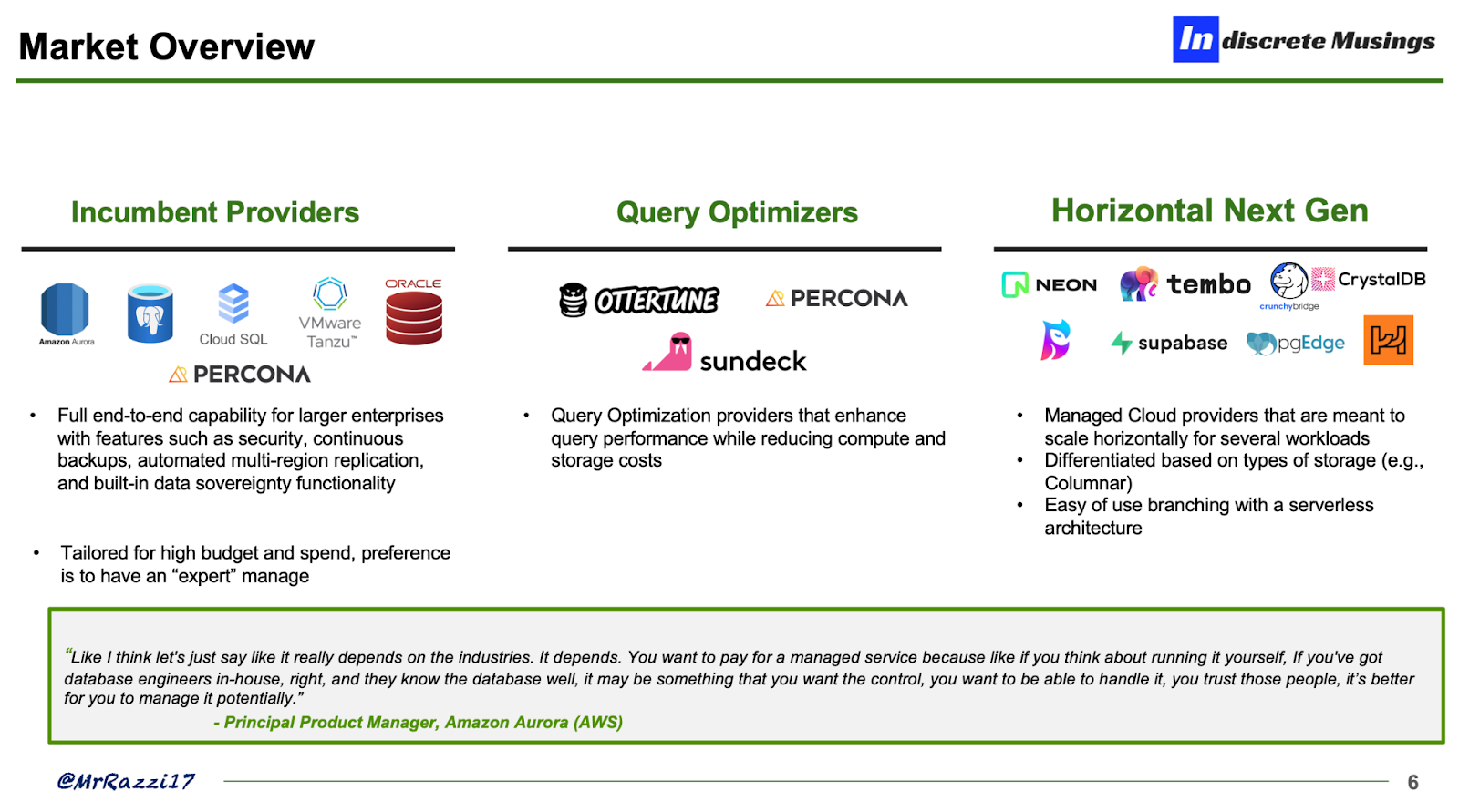
With all the momentum around Postgres, I segmented the market into three categories:
Incumbent Providers (e.g., AWS, Oracle)
Full end-to-end capability for larger enterprises with features such as security, continuous backups, automated multi-region replication, enterprise-build SLAs
Tailored for high budget and spending, the preference is to have an outsourced “expert team” to manage the relational databases.
Query Optimization (e.g., Ottertune, Sundeck)
Query optimization specializes in improving the performance and efficiency of databases.
Talent arbitrage, providing an “expert in a box” service, and overall optimization also leads to decreases in database costs over time.
Usually able to support more than one RDBMS
Next Generation Providers (e.g., Neon, Hydra, Supabase, PostgresML)
Managed Cloud providers that are meant to scale horizontally for several application workloads (e.g., Generative AI)
Differentiated based on types of storage (e.g., Columnar)
Ease of use branching with a serverless architecture in addition to separation of storage and compute (“new age architecture”)
As it relates to the “Next Gen” providers, one of the most significant topics discussed to date is rethinking the architecture to deploy Postgres. Historically, managed cloud or self-hosted Postgres would look something like this:

While in theory, this approach makes sense, considering relational databases are tied directly to storage. However, if a user wants to get more throughput or storage, a user has to migrate to larger host machines. As a result, the managed provider has to oversee the migration procedure to avoid downtimes explicitly. Also, within this architecture, failovers prove costly, and you’re left paying more for storage and computing.
With serverless, on the other hand, developers don’t have to think about the underlying infrastructure. They can scale their respective applications while the cloud provider takes care of provisioning the servers—concerning databases, actual serverless offerings allow for the separation of storage and compute while substituting the storage layer with a redistribution layer across clusters of notes, usually Kubernetes. I’m starting to see more serverless Postgres providers in addition to the standouts, such as AWS Aurora and Neon.

The benefit of using a managed serverless Postgres provider is that users don’t have to worry about sizing; often, they only need a connection string to the database regardless of size/scale—unlocking true scalability.
Additionally, companies with consumption-based pricing can scale down to zero (and actually pay zero), making the economics of using the database more predictable and affordable. One of the most exciting product enhancements has been copy-on-write branching, made famous by Neon, which allows developers to run a dedicated database for every preview or GitHub commit, effectively allowing developers to create a full copy of their data with a separate endpoint to it in the event you want to run it in your CI/CD pipeline, testing, and more.
With serverless, you’ll run into cold-start times and some invoking issues. Still, generally speaking, I’m excited about this new-age approach and eager to see a handful of start-ups adopting this architecture.
Favorable Conditions

After speaking with several experts and understanding the nuances of Postgres, it’s clear that the relational database and the appetite from users and buyers are immensely favorable. It’s unclear what the winning combination will look like, but we’re undoubtedly on the precipice of a significant shift within the relational database world. So, in ending, I leave you with a list of particulars about the market and what attributes one needs to encompass, or more or less, my thesis:
Separate storage from the compute, key mandate across several buyers
Must support a managed version of branching (e.g., for prod) for both on-prem and cloud environments
The initial wedge for a provider should be focused on SaaS, considering the velocity of products and the need for reduced costs with scale (bonus for Generative AI applications)
New age provider with a separate storage/compute must be able to support on-demand scalability and bottomless storage (e.g., fault-tolerant and integrated with object stores)
Analytics-specific projects provide immediate value and are less saturated (e.g., no switching costs, just greater visibility)
I hope to revisit my points of view on the world of Postgres to see how much I got wrong and right. If you think I’m dead wrong and missing crucial components to my thinking, please don’t hesitate to reach out so I can further stretch and refine my reflection in the space!
Additionally, if you’re building something within managed Postgres, I’d love to chat with you! Feel free to drop me a note at zain [at] ridge.vc or a line on Twitter @MrRazzi17.
Thanks to Adam Fletcher, Johann Schleier-Smith, Patrick DeVivo, Eyal Manor, and others who have challenged my assumptions and stretched my boundaries!